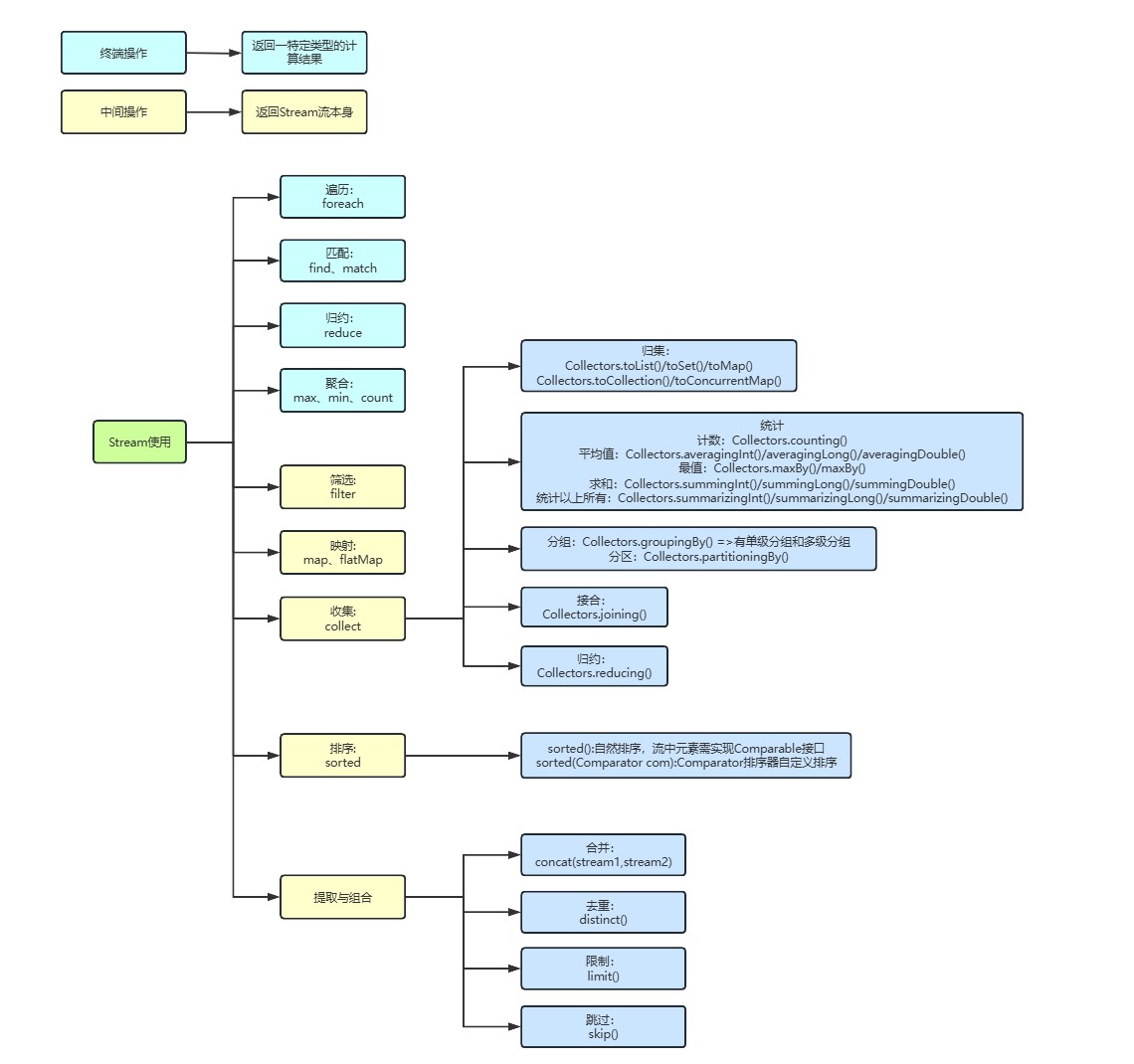
JDK8开始新增的一套API,主要操作集合和数组数据,代码简洁可读性高
核心方法filter()(筛选)、map()(转换)、collect()(收集)
支持并行流(parallelStream())提升大数据量处理效率
常见操作
- filter():筛选,返回符合条件的元素
- map():映射,返回指定结果
- collect():收集,返回结果
- forEach():迭代,对集合中的元素进行迭代
- reduce():归约,将集合中的元素进行归约为一个结果
demo
package com.jysemel.java.basic;
import lombok.Data;
@Data
public class User {
private String name;
private Integer age;
public User(String name, Integer age) {
this.name = name;
this.age = age;
}
}
package stream;
import com.jysemel.java.basic.User;
import org.junit.jupiter.api.Test;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
public class StreamDemo {
@Test
public void dd(){
// 初始化用户列表
List<User> userList = new ArrayList<>();
userList.add(new User("A", 20));
userList.add(new User("B", 17));
userList.add(new User("C", 25));
userList.add(new User("D", 16));
// Stream流方式:一站式完成筛选、转换、统计
// 1. 筛选成年用户并提取姓名
List<String> adultNames = userList.stream()
.filter(user -> user.getAge() > 18) // 筛选条件:年龄>18
.map(User::getName) // 提取姓名(方法引用)
.collect(Collectors.toList()); // 转换为List
// 2. 统计成年用户数量
long adultCount = userList.stream()
.filter(user -> user.getAge() > 18)
.count(); // 直接统计数量
// 3. 拼接姓名
String nameStr = String.join(", ", adultNames);
System.out.println("用户姓名:" + nameStr);
System.out.println("用户数量:" + adultCount);
}
}
常见操作步骤
创建入口
从集合创建
List<String> list = Arrays.asList("a", "b", "c");
Stream<String> stream = list.stream(); // 顺序流
Stream<String> parallelStream = list.parallelStream(); // 并行流
从数组创建
// 使用 Arrays.stream()
String[] array = {"a", "b", "c"};
Stream<String> stream1 = Arrays.stream(array);
Stream<String> stream2 = Arrays.stream(array, 1, 3); // 截取部分元素
// 使用 Stream.of()
Stream<String> stream3 = Stream.of(array);
Stream<Integer> stream4 = Stream.of(1, 2, 3); // 直接传入元素
从文件创建
Path path = Paths.get("data.txt");
try (Stream<String> lines = Files.lines(path)) {
lines.forEach(System.out::println);
} catch (IOException e) {
e.printStackTrace();
}
其他 API 创建
// 随机数流
Random random = new Random();
IntStream randomInts = random.ints(5, 10, 100); // 5个10~99的随机数
// BufferedReader 行流
BufferedReader reader = new BufferedReader(new FileReader("file.txt"));
Stream<String> lines = reader.lines();
// 正则分割
Pattern pattern = Pattern.compile(",");
Stream<String> splitStream = pattern.splitAsStream("a,b,c");
中间流程
filter(过滤出满足条件的元素)
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);
stream.filter(n -> n % 2 == 0) // 保留偶数
.forEach(System.out::println); // 输出 2 4
distinct(去除重复元素)
Stream.of(1, 2, 2, 3, 3, 4)
.distinct()
.forEach(System.out::print); // 1234
map(将元素映射为另一个元素)
Stream.of("a", "b", "c")
.map(String::toUpperCase)
.forEach(System.out::print); // ABC
limit(截取元素)
Stream.iterate(0, i -> i + 1)
.limit(5)
.forEach(System.out::print); // 01234
sorted(排序)
Stream.of(3, 1, 4, 1, 5)
.sorted()
.forEach(System.out::print); // 11345
Stream.of("aa", "b", "ccc")
.sorted(Comparator.comparingInt(String::length))
.forEach(System.out::println); // b aa ccc
尾端操作
匹配与查找(返回布尔值或 Optional)
流中任意一个元素满足条件返回 true
boolean hasEven = Stream.of(1, 2, 3).anyMatch(n -> n % 2 == 0); // true
归约(将流归约为一个值)
int sum = Stream.of(1, 2, 3).reduce(0, Integer::sum); // 6
收集(将流元素累积到容器中)
// 收集为 List
List<String> list = Stream.of("a", "b", "c").collect(Collectors.toList());
// 收集为 Set
Set<String> set = Stream.of("a", "b", "a").collect(Collectors.toSet());
// 收集为 Map
Map<Integer, String> map = Stream.of("a", "bb", "ccc")
.collect(Collectors.toMap(String::length, Function.identity(), (v1, v2) -> v1));
// 连接字符串
String joined = Stream.of("a", "b", "c").collect(Collectors.joining(", ")); // "a, b, c"
// 分组
Map<Integer, List<String>> groupByLength = Stream.of("a", "bb", "c")
.collect(Collectors.groupingBy(String::length)); // {1=["a","c"], 2=["bb"]}
// 分区
Map<Boolean, List<Integer>> partition = Stream.of(1,2,3,4)
.collect(Collectors.partitioningBy(n -> n % 2 == 0)); // {false=[1,3], true=[2,4]}
遍历(产生副作用)
Stream.of(1, 2, 3).forEach(System.out::println); // 可能乱序